Learn what steps Google takes in finding and discovering new content on the Internet. With the help of Google patents, we take a deep dive into crawl scheduling, Google data centers, crawl budget and crawl behaviors.
Crawling is the process by which search engines discover new and updated pages to their index. In this section, we’ll walk you through how Google’s bot (aptly called Googlebot) crawls the web.
Googlebot uses an algorithmic process involving computer programs which help determine which sites it should crawl, how often a site (or page) should be crawled, as well as how many pages to fetch from a site.
This process begins with a list of URLs that is generated from a previous crawl process and is augmented with the Sitemap data that is provided by the webmaster.
By visiting each website, Googlebot detects and keeps track of any links discovered on each page to crawl at a later stage. Any new discoveries (new sites, updated sites, dead links) are logged and updated in the Google index.

How Does Google Know Which Pages Not to Crawl?
- Pages that are blocked in the robots.txt file will not be crawled, but still might be indexed if they are linked to by another page. Google is able to infer the content of a page by following the link that is pointing to it, and index the page without actually parsing its contents.
- Google cannot crawl any pages that are not accessible by an anonymous user – this includes any login or other authorisation protection.
- Pages that have already been crawled and are considered duplicates of another page are crawled less frequently.
Scheduling Crawls
The World Wide Web is constantly growing with millions upon millions of new web pages being created and published. It’s important to remember that search engine crawlers have a capacity in terms of how many pages they can crawl, and how often. Search engines need an efficient and effective way to determine how and when these pages should be crawled.
In 2010 and 2011, Google patented a systematic method for automatically selecting and scheduling which documents should be crawled based on certain criteria without putting a strain on its servers. This is done by assessing, logging and prioritising which URLs should be crawled, assigning crawl period intervals and creating a schedule for when the bots should crawl them.
We already know that links are at the heart of Google’s crawling process, and that’s exactly the case with the patented system, which discovers links in the following ways:
- Direct submissions of URLs i.e. pages that are submitted by webmasters
- Crawling of URLs i.e. looking at the outgoing links on crawled pages
- Submissions of content containing links from third parties i.e. RSS feeds
In this section, we’ll walk you through how Google deals with the pages once they’ve been discovered.
Crawling Layers
Google stores document identifiers in a data structure that is composed of three separate layers. Google then assigns a crawl score to each URL. This is based on factors such as how frequently the pages are updated, what their PageRank score is and so on. This determines which layer the document should be assigned to.
Web pages that are assigned a high crawl score are passed onto the next stage (i.e. upgraded from base layer to daily crawl layer). Whereas URLs with a low crawl score are not passed onto the next stage for the next crawling period.
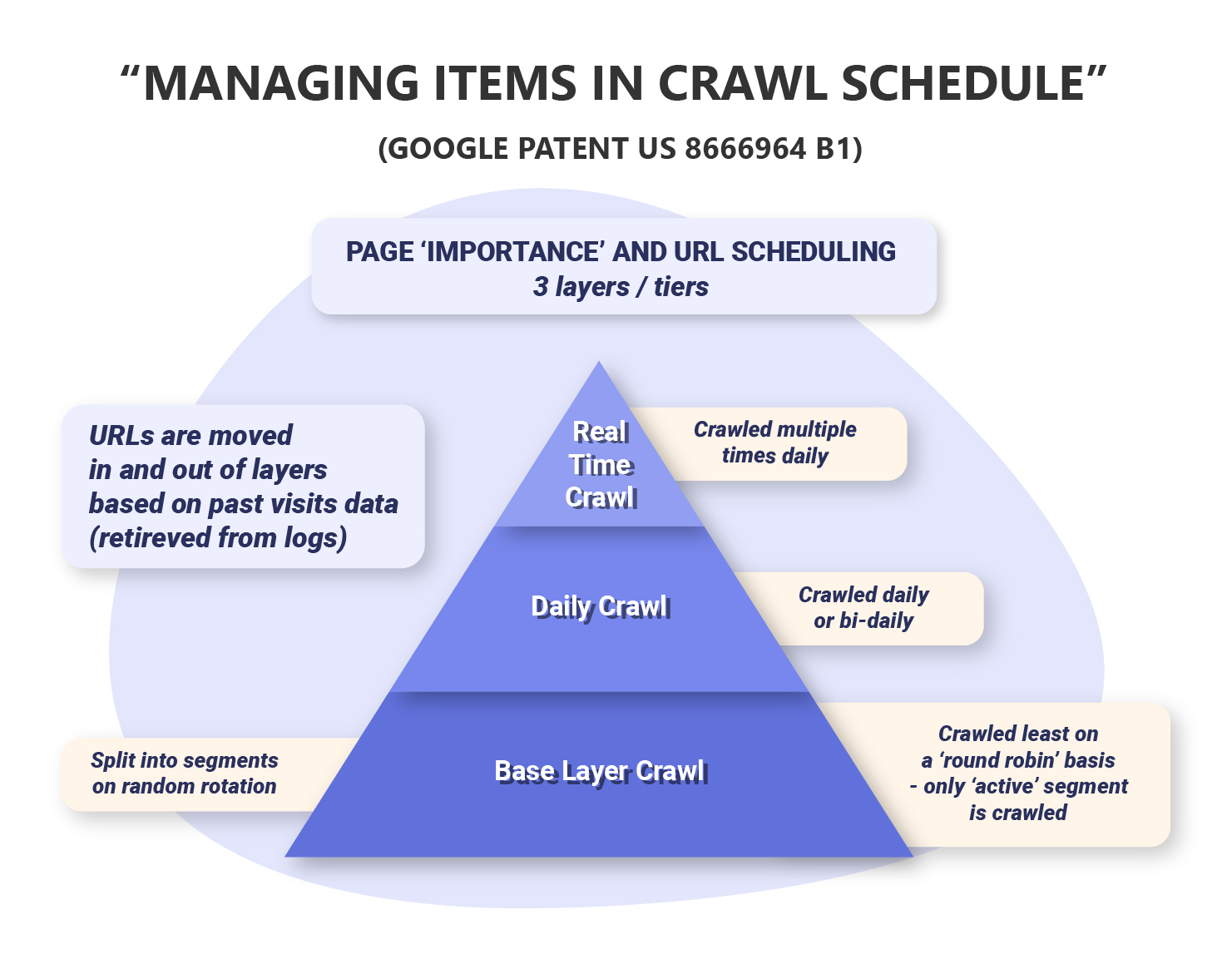
Base Layer
The base layer of this data structure is split into a sequence of segments which includes a number of URLs that represent a percentage of the addressable URLs spanning the entire Internet.
A controller (aka the URL Scheduler) then selects one of these segments (referred to as the active segment) to be crawled periodically (i.e. daily) in a round robin manner until all segments have been visited by the robots programs.
Active segment – the segment of URLs that is selected by the controller to be crawled.
Daily Crawl Layer
The daily crawl layer consists of a smaller group of URLs that either have a higher crawl score, crawl frequency or both. This layer also includes high priority URLs that are discovered by the crawler during the active segment.
Real Time Layer
The real time layer contains an even smaller group of pages which are assigned even higher crawl scores or crawl frequencies. These URLs are crawled multiple times during a given period i.e. multiple times a day. This layer may also contain high priority URLs that have been newly discovered and need to be crawled as soon as possible.
The Logs
When a URL is discovered by the crawler, it may collect various information about the page and store them in various logs – these can be thought of as the “clerks” who keep a record of the URL.
Link Logs
The link log stores a list of outbound links of the crawled page. This information is passed onto content filters which check for duplicate content on the page, duplicate file structures as well as the anchor text used within those links.
History Logs
As you may have guessed, the history logs contain a record of how frequently the content that is associated with the URL(s) is changing, this is referred to as the URL change frequency.
URL change frequency – a calculation that determines how frequently a URL has changed as well as a note on the last updated date.
A change weight is also considered – this is to distinguish the importance of the change i.e. changing a couple of sentences is not the same as adding an entire paragraph to an article. The history log also contains other identifying information such as:
- URL Fingerprint – essentially an ID for the URL
- Timestamp – indicated the time that the URL was recorded/crawled
- Crawl Status – indicates whether the URL was successfully crawled or not
- Content Checksum – a numerical value which refers to the content of the downloaded page, if the download was successful. This is what is used to determine when the content on the page has been changed.
- Source ID – indicates how the URL was discovered by the robot, i.e. via an outbound link or an internal repository of documents
- Download Time – how long it took the robot to download the web page
- Error Condition – records any errors that were encountered when attempting to download the web page
- Page Rank – a score computed for a given URL by looking at the number of outbound links pointing to a URL and the page rank of those referencing URLs
URL Scheduler
The URL Scheduler (also referred to as the controller by some texts) is essentially the component that is doing most of the heavy lifting – it’s the supervisor.
Here are some of the jobs that the URL scheduler does:
- Decides which pages Googlebot visits in a given period (or epoch) and stores this information in the data structure.
- Selects a segment from the base layer for crawling.
- Determines whether to add or remove URLs from the daily layer and the real-time layer based on information stored in the history logs.
- Decides how regularly each page should be visited by Googlebot.
- Obtains and analyses the URL change frequency.
- Checks the importance of a page when scheduling visits from Googlebot.
Scoring Functions
Let’s take a look at some of the scoring functions that Google uses to prioritise which pages should be crawled.
Daily Score – The daily score determines which URLs should be added to the daily crawl or real-time layers.
Keep Score – Sometimes, the URL scheduler may “drop” a URL from the system to make room for new URLs. In order to decide whether or not a URL should be dropped, a Keep Score is assigned.
Crawl Score – The crawl score, as we already know, determines the importance of the URL during the crawling process. This is computed using factors like:
- The current location of the URL (active segment, daily layer or real-time layer)
- URL page rank
- URL crawl history which may be computed as: crawl score = [page rank] ^ 2 * (change frequency) * (time since last crawl)
CrawlRank
You’re probably wondering how any of this impacts your website. Well, having this insight actually answers one pretty common question:
Why isn’t Google crawling (and by extension indexing) some of my pages?
Apart from technical factors (which we’ll tackle later on in the course) that may be preventing some of your pages from being crawled, it’s possible that the bottom line may just be that Google doesn’t see any value in them.
In other words, the CrawlRank (crawl score) for those pages is so low, that Google keeps pushing it down the queue.
Moreover, the fact that PageRank (which again, we’ll tackle in much more detail later on) plays such a big role in whether Googlebot crawls your web page(s), puts further emphasis on ensuring that you’re creating the best possible content and user experience for your audience.
PageRank is a relative score of importance and authority by evaluating the quality and quantity of its links.
Google Data Centers
According to Google, a data center is “a facility with many computers that store and process large amounts of information.”
All that web crawling, indexing, and searching takes enormous amounts of computing power, not to mention all of the other products and services that Google offers like GMail and Google Cloud etc.
Whatever Google product you’re using, you’re using the data centers’ power to do it.
In fact, Google’s employees describe their data centers as “the brains of the Internet”, “the engine of the Internet” in the video below, and rightly so.
Each data center serves as a single “node” in a larger network of data centers that is located across the world – from Ireland and Chile to India and Singapore!
Google uses distributed crawling to retrieve and discover new data via their data centers.
Distributed crawling is the process where crawlers in a given data center crawls the web servers that are topologically close by, and then propagates the crawled pages across the entire network of peer data centers.
For example, the data center in Singapore will crawl web pages from web servers that are close by, and then distribute it to the other data centers that Google has.
The obvious benefit of this is it enables Google to mine the web much more efficiently as each data center only has to focus on crawling the pages that are geographically served close to it.
In a Google patent that was filed in 2007, we can see that data centers are used for several other jobs during the crawling process. For example, when a web crawler discovers new content, it relays this information to the Data Center.
The Data Center then conducts at least one of the following steps:
- Storing the new or changed content
- Storing delta changes of a page (small changes)
- Data mining
- Data processing
- Application of data to at least one search engine
- Intelligent caching
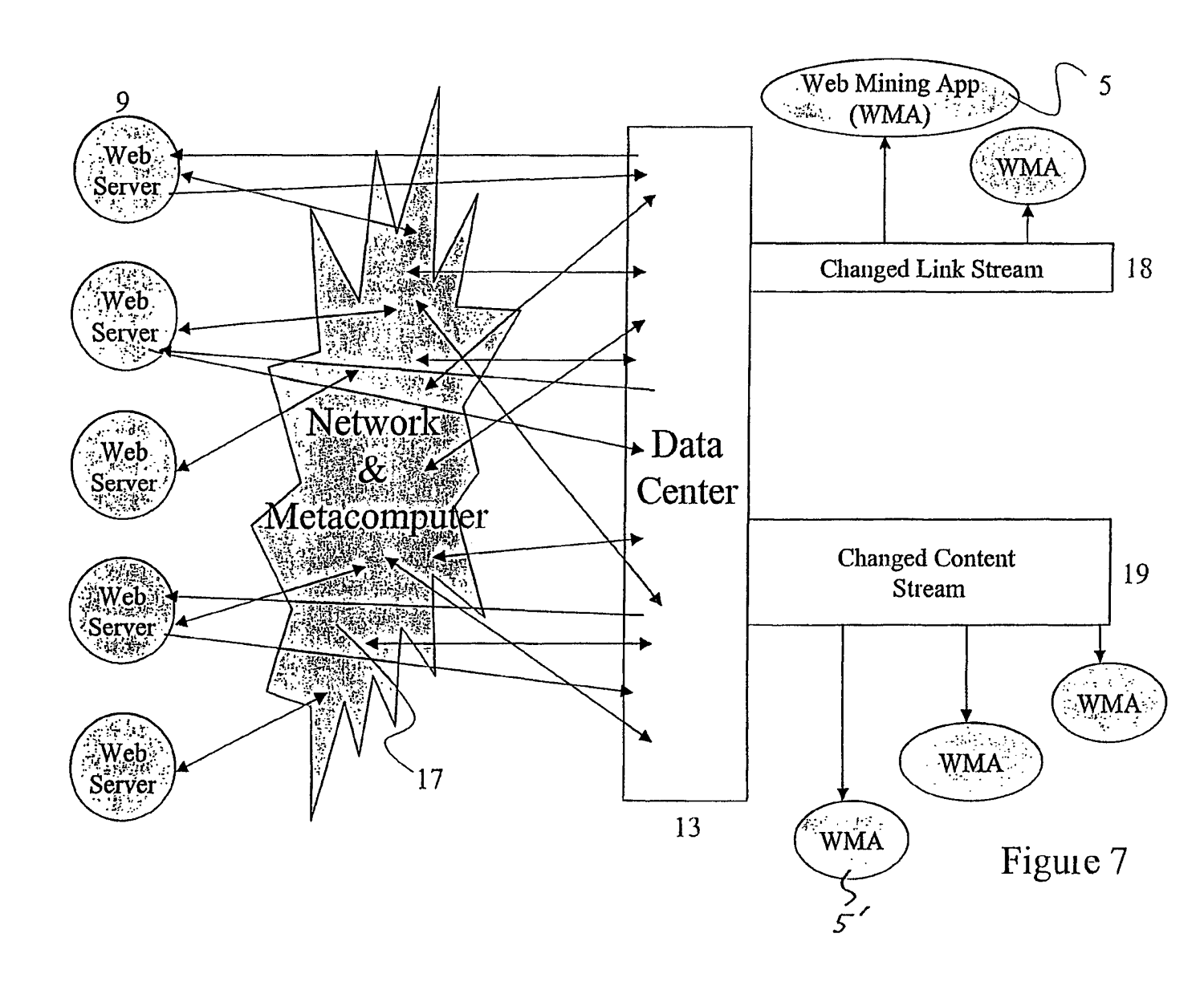
As seen in the diagram above, data centers consist of web mining applications and are in communication with a network of web crawlers. When the crawlers discover new information, the data centers produce a changed link stream and a changed content stream (both of which are identifiers used to denote changes between different versions of a web page that has been crawled).
Web mining applications are programs that extract the contents of the web page that is crawled.
These are propagated to the web mining apps which then process, download and store the contents of the pages.
Google Crawling Patents
We’ve seen a couple of patents that Google have been granted for their crawling system earlier in this module. However, as you’ve probably guessed, those aren’t the only ones. In this section, we’ll walk you through three more patents that may help give an insight into how Google crawls the Internet.
Anchor Tag Indexing in a Web Crawler System
Originally filed in 2003 and granted in 2007, this patent, titled Anchor Tag Indexing in a Web Crawler System, potentially answers a few important questions like:
- How do search engines use the anchor text in the links pointing to certain pages?
- How are permanent and temporary redirects treated differently by search engines?
Previously in the module, we showed how Google determines how often a page should be crawled based on several factors and formulas. Another factor that comes into play when it discovers a new URL or document, is the anchor text that is used to link to this page.
The reason why the anchor text is important, is because it helps provide contextual information about the page before Google even looks at the contents. This is especially important and beneficial if the page we’re looking at contains little to no text; the same applies to image and video files.
Anchor Text Indexing
The patent introduces the concept of an anchor map (in addition to link logs which you will remember from the Scheduling Crawls section).
The anchor map contains information about the text that is associated with the links including a number of anchor records that indicate the source URL (i.e. the page where the link was discovered), as well as the URLs of the target pages.
These records are ordered by the documents that they target and may also contain annotation information about the anchors.
The annotation information that is stored may be used in conjunction with other information to determine how relevant a page is to different search queries.
For example, the system may encounter a link pointing to a web page containing a chocolate cake recipe with the text “to view the recipe click here”.
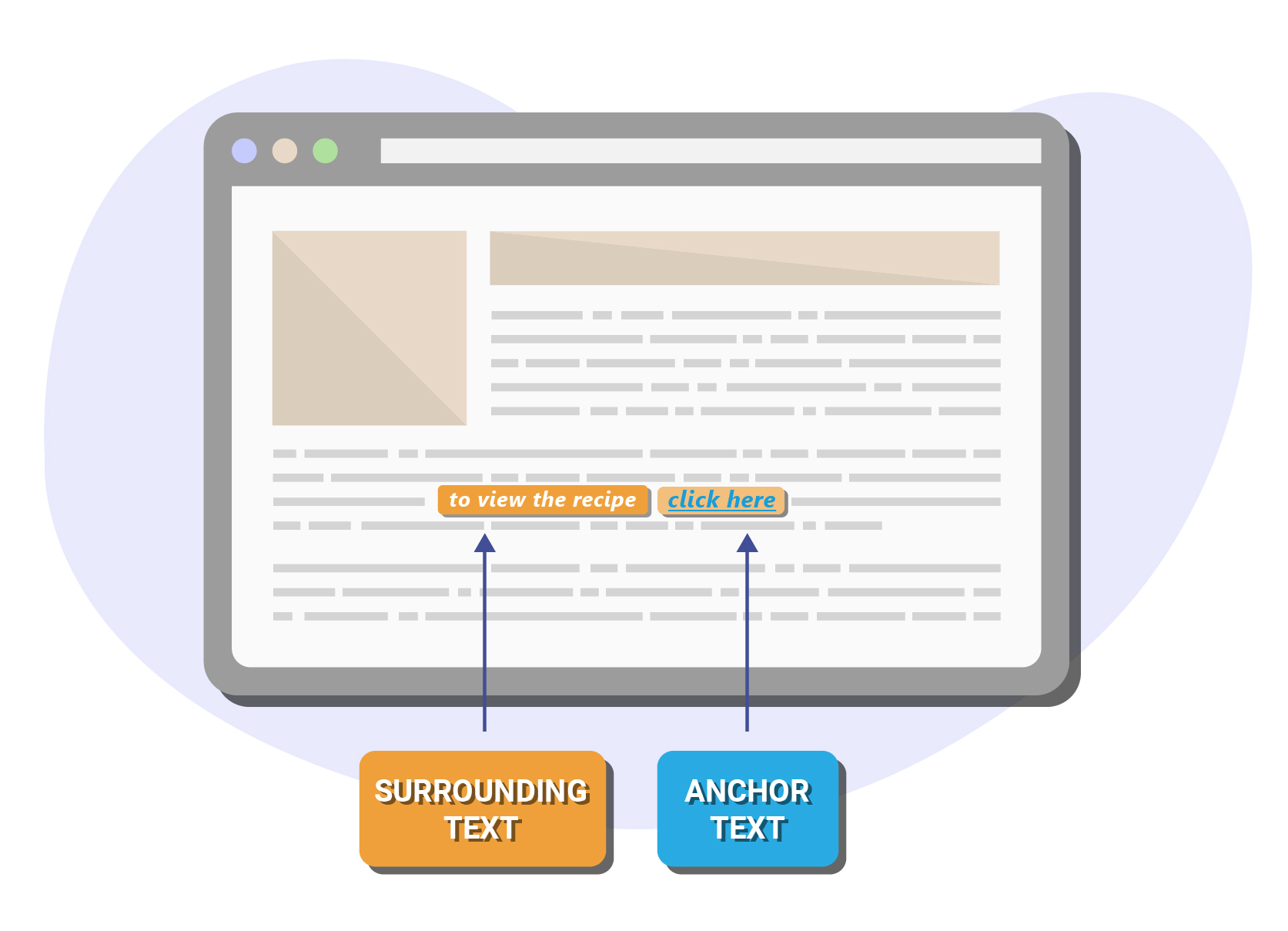
Although the anchor text might be “click here”, Google may also keep a record of the additional surrounding text “to view the recipe”.
Without this crucial piece of information, it would be incredibly difficult to glean the context and connection between the two linked pages i.e. that the link is pointing to a recipe page.
Anchor maps are also useful for identifying duplicate content, which is something that Google condones as it offers very little value to the user. In these cases, the anchor text pointing to duplicate pages is used to crawl and index the canonical (most important) version of the page.
Handling Redirects
The patent also shines some light on how search engines treat links with temporary or permanent redirects.
Instead of following permanent redirects that are found at the URLs that have been requested for crawling, the source and target URLs (that have been redirected) are sent to the content filters which place these links in the link logs where they are passed to the URL managers.
In this context, the URL managers are used to determine when and if these permanently redirected URLs should be crawled by a robot.
For temporary redirects, the robots will follow and obtain information about the page.
Configuring Web Crawler to Extract Web Page Information
This patent titled ‘Configuring web crawler to extract web page information’ which was filed in 2014 and granted two years later, details how Google’s web crawler is configured to extract the information from a web page.
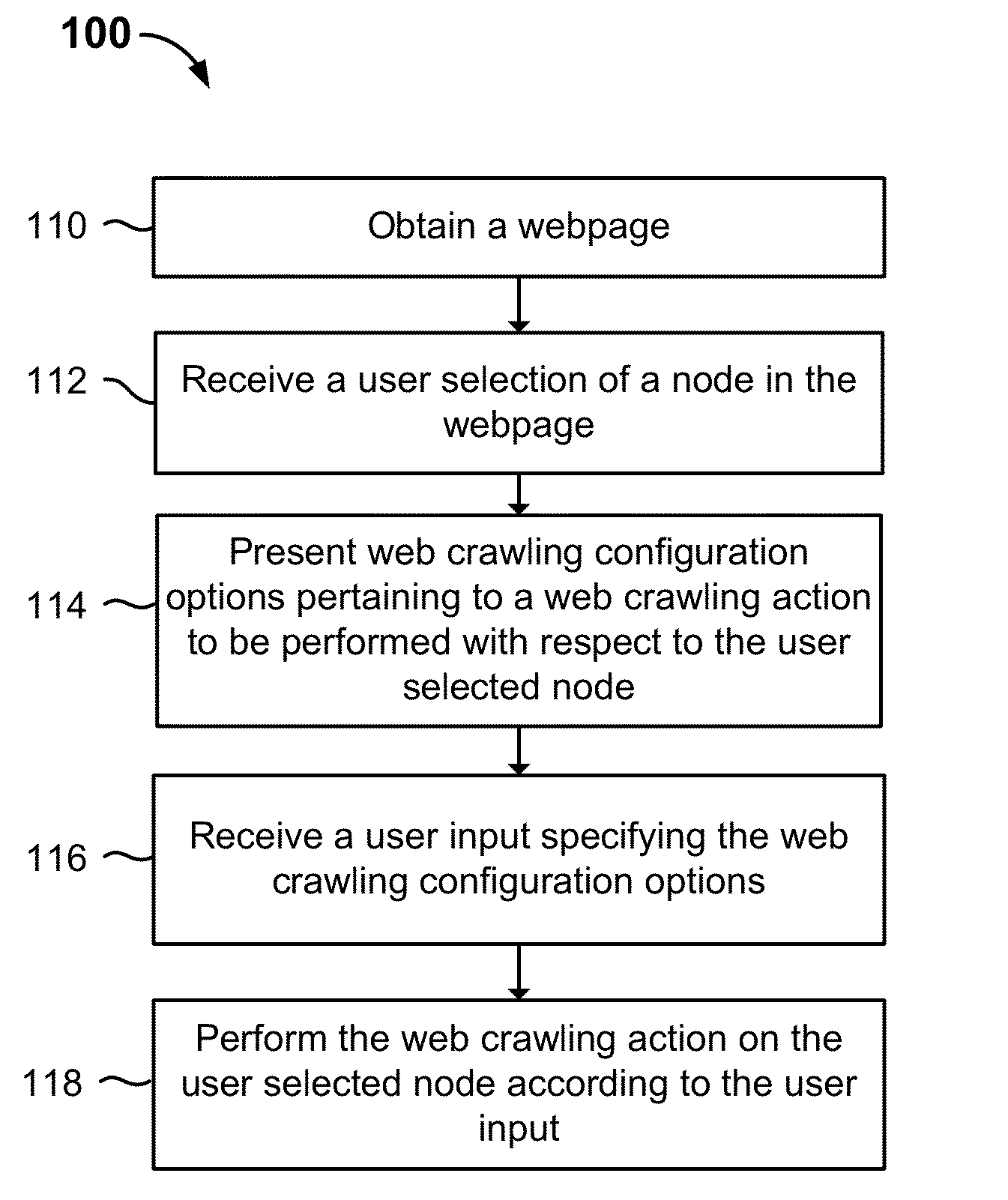
The above screenshot which is taken from the patent depicts the process that Google’s program takes in order to extract the information from a web page during the crawling process.
Let’s walk through this process in detail.
110 – Obtain the web page that is to be configured and crawled.
112 – A user selection of a node in the webpage is received. This can be indicated by a click, highlight text with a mouse, double clicking, pressing a button or key, tapping, touching or highlighting etc.
114 – Web crawling configuration options are presented based on the node that the user selected.
An example from the patent is as follows. If the node is made up of text followed by a submission button, the configuration options for web crawling actions related to extract text and a form submission action would be presented.
In other words, the system determines what it is “seeing” and then decides how to extract the information from what it’s seeing.
There are several different elements that the web crawling configuration may encounter i.e. text, links, images, events, sub pages and form elements.
116 – At this stage of the process, the configuration option for the crawling process is selected by the user input. For example, for a login page, the user must enter their username and password into a web form. When the web page is crawled by Googlebot, it automatically enters the username and password provided by the user into the textbox.
118 – At the final stage, the web crawling action defined by the user input is performed and the web page is crawled according to the configuration option settings as indicated by the user when configuring the web page for crawling. For example, the user selected a picture from a product page on an online store and indicated that they wanted to download the image and extract alternative text.
To summarise, this patent helps us see how Google breaks down the various elements on a web page (such as text and images), and determines what action it needs to take in order to extract the desired information so that it can be indexed.
Duplicate Document Detection in a Web Crawler System
In some of the previous patents that we’ve encountered, we’ve touched upon the fact that Google’s programs are actively looking out for and keeping a record of pages that contain duplicate content.
Well, it should come as no surprise then, that they’ve also been granted a patent that specifically focuses on detecting duplicate documents during the web crawling process aptly titled ‘Duplicate document detection in a web crawler system’.
Why is detecting duplicate content so important?
Let’s look at one of the reasons given in the patent itself: “For example, on the back end of a search engine, if duplicate copies of a same document are treated as different documents not related with one another in terms of their content, this would cause the search engine to waste resources, such as disk space, memory, and/or network bandwidth, in order to process and manage the duplicate documents.
On the front end, retaining duplicate documents would cause the search engine to have to search through large indices and to use more processing power to process queries. Also, a user’s experience may suffer if diverse content that should be included in the search results is crowded out by duplicate documents.”
In a nutshell – Google wants to focus on crawling and indexing unique pages that will be valuable to the end user.
The patent details some of the previous concepts that were highlighted in the earlier patent, but delves deeper into how the content filter works alongside the duplicate content server (also referred to as the Dupserver) to detect duplicate content.
It’s worth noting that the patent defines duplicate content as “documents that have substantially identical content, and in some embodiments wholly identical content, but different document addresses”.
It goes onto categorise three scenarios where duplicated content is encountered by the web crawler:
- Two pages are considered duplicate documents if they share the same content but have different URLs.
- Two temporary redirect pages that share the same target URL, but have different source URLs.
- A normal web page and temporary redirect page where the normal web page’s URL is the target URL of the temporary redirect page. Or, if the content on the normal web page is the same as the temporary redirect page.
The patent also details the various methods that it may use to detect duplicate content.
Content Fingerprint Table
One of these methods is via fingerprint identification, which involves using fingerprints of the content that is found on the pages to compare between other known documents. This information is stored within content fingerprint tables.
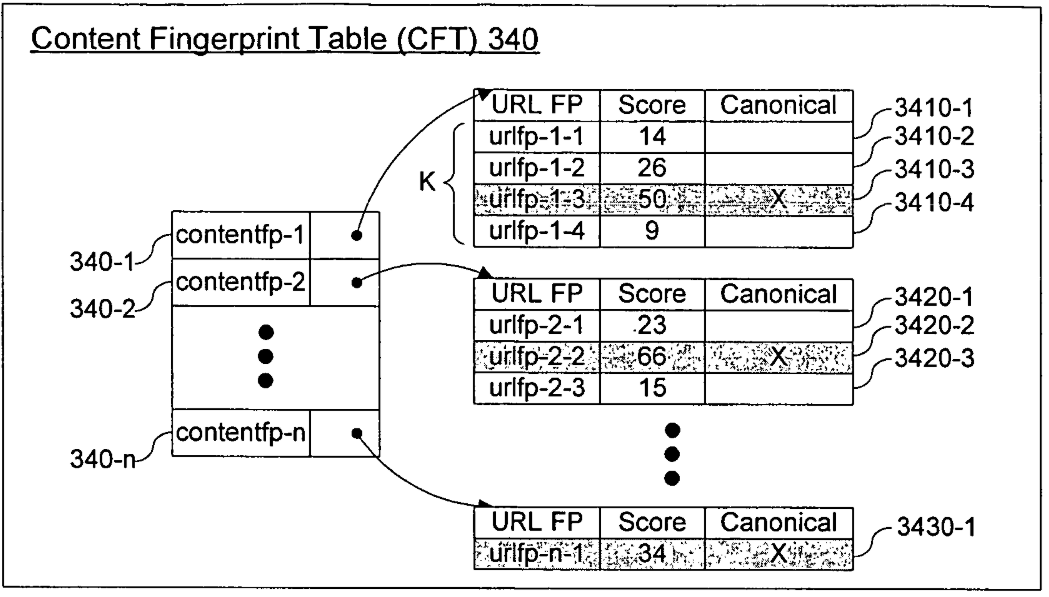
When receiving a newly crawled page, the content filter will likely first consult the Dupserver to see if a copy of the web page already exists by performing a content fingerprint table lookup. If one exists, then the CFT is updated with an identifier for the newly discovered page.
URL Fingerprint Table
A URL Fingerprint Table is also used to determine which page should be treated as the canonical version using what’s aptly called a URL fingerprint table lookup.
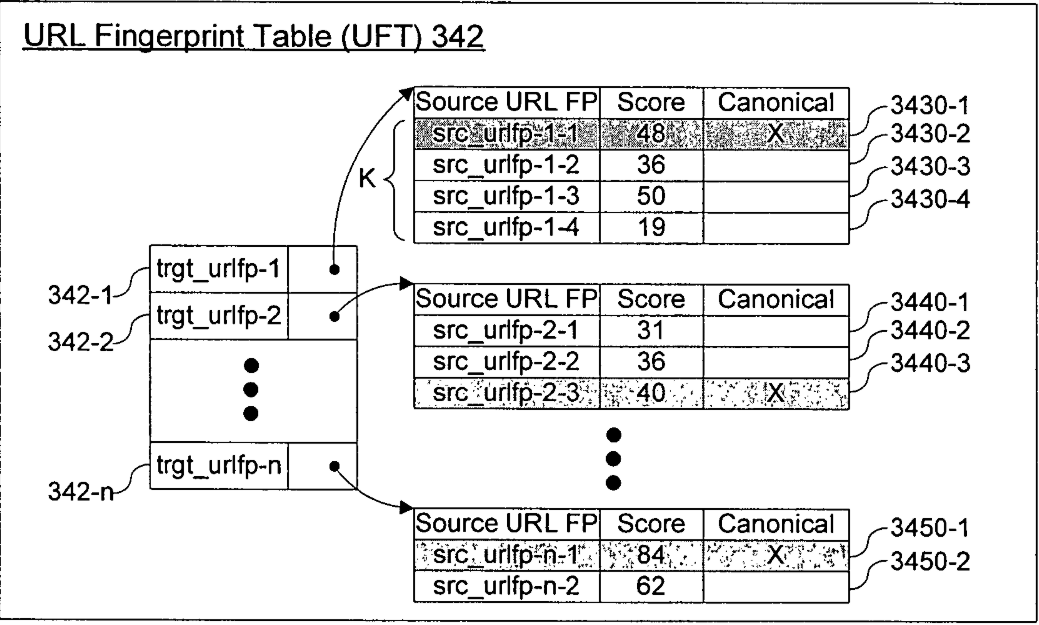
While executing the UFT lookup, the Dupserver determines whether the newly crawled
webpage is the canonical page with respect to the page’s target URL.
Once this has been done, the final action that the content filter and Dupserver perform is the URL “clean up”. This involves taking the URL fingerprints of each URL in the newly crawled page that corresponds to a page that has been permanently redirected to another target page, and replacing it with the URL fingerprint of the target page.
When choosing the canonical, it’s important to note that the page with the highest PageRank (for example) may not always be the one that is selected.
Instead, the patent states that there may be cases where “a canonical page of an equivalence class is not necessarily the document that has the highest score (e.g., the highest page rank or other query-independent metric).”
The example given in the patent suggests that Google may keep a record of all of the duplicated pages that it finds, and that when it comes across a newly discovered duplicate, it may look at the PageRank (or another independent ranking factor) to see if the new URL has a significantly higher PageRank.
Crawl Budget
There are several factors that affect the way search engines will treat the content on your website. Crawl budget is one of them. Understanding crawl budget will help you ensure that your website is crawled effectively by Googlebot.
Coined by SEOs to describe the frequency at which Googlebot (or any web crawler for that matter) visits your website. It wasn’t until September 2017 that Gary Illyes from Google broke the silence with an official definition of crawl budget. And importantly, what it means for Googlebot.
According to Illyes, Crawl Budget = Crawl Rate Limit + Crawl Demand
Crawl Rate Limit
The crawl rate limit is the maximum number of times that Googlebot can make a request to crawl a given site. This way, Googlebot will not overload your website with too many requests. The CRL is determined by your site’s health. For instance, a fast loading website will have a higher CRL than a website that has slow response times.
Crawl Demand
Crawl demand, is how often Google wants to crawl the pages on your site – this is based on the popularity and staleness of the content. In other words, the aim for Google is ensure that its index is kept as fresh as possible – so the most popular pages, and pages that haven’t been visited by Googlebot in a while, are likely to be crawled more frequently.
If we take the two together, we can deduce that Crawl Budget can therefore be defined as the “number of URLs that Googlebot can and wants to crawl”.
How Crawl Budget Affects Your Chances of Ranking
The ultimate question is whether any of this is going to help you rank, right?
The answer is both a yes, and a no.
Google has confirmed that an increased crawl rate does not necessarily lead to ranking better in the SERPs. That’s because there are hundreds of other (arguably more important) signals that Google uses to determine whether a page should rank or not.
So, whilst the crawl budget may not be a ranking signal, it’s still an important aspect of SEO as if Google doesn’t index a page (for whatever reason), it’s not going to rank for anything.
A Brief History Lesson On Crawl Rate
Once upon a time, Google kindly allowed you to increase the crawl rate in Google Search Console.
Although this feature is no longer available, you can file a special request to reduce or limit the crawl rate if you notice that your website’s server load times are being impacted by Googlebot hitting your server too hard.
Understanding Crawl Behaviours
In this section, we’ll explore some of the ways that search engines may traverse your website and how your site structure and server speed may impact Google’s crawl behaviour.
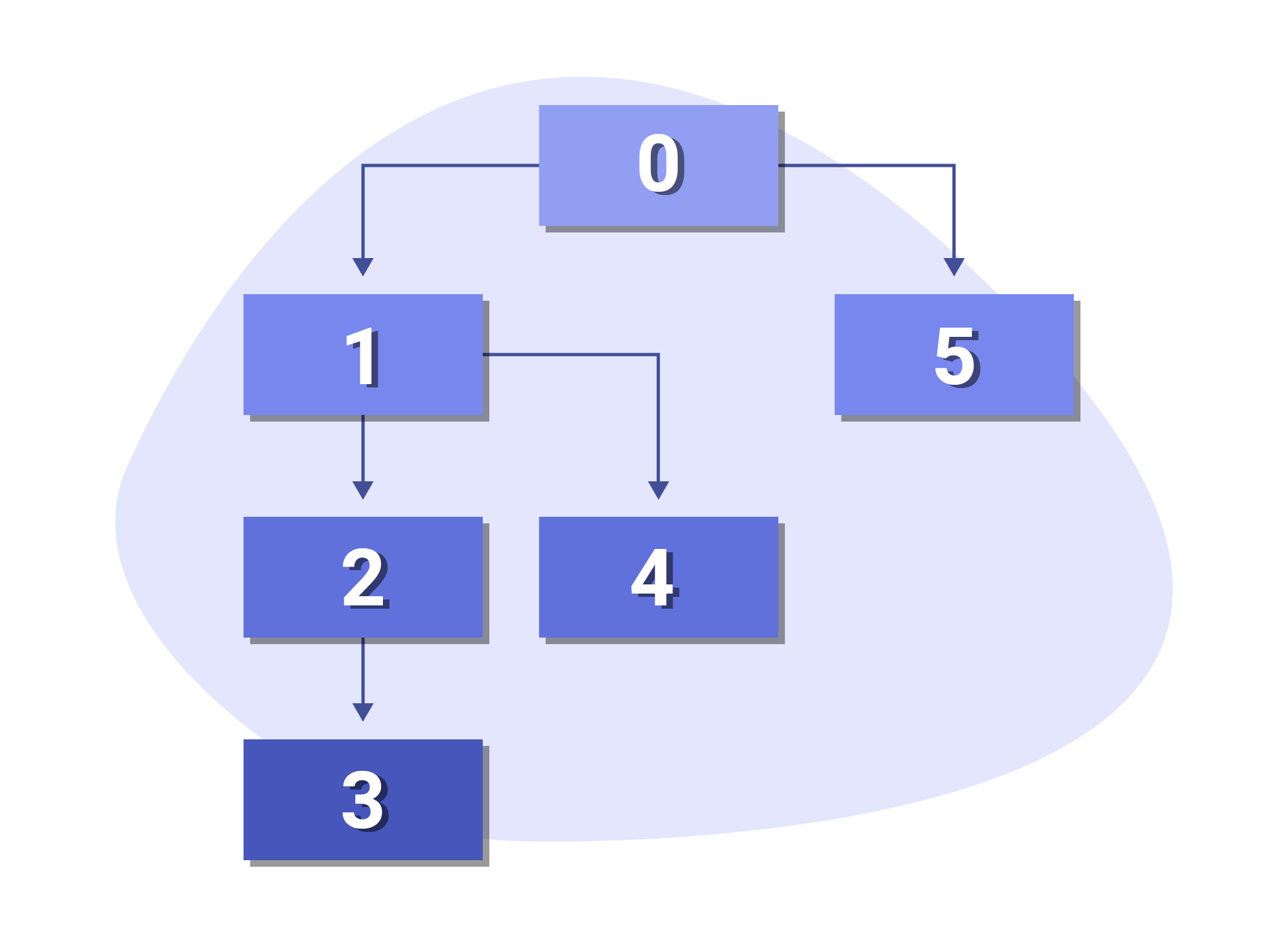
Depth First Search Crawling
Depth First crawling forces web crawlers to explore the depth of your website before returning back up the site hierarchy.
This proves an especially effective method for quickly identifying internal pages that contain valuable content.
On the flip side, this means that core navigational pages will be pushed down in priority. So if your site structure has lots of levels, then DFS search would not be beneficial as the crawler may focus on crawling irrelevant internal pages as opposed to important landing pages that are higher up the hierarchy.
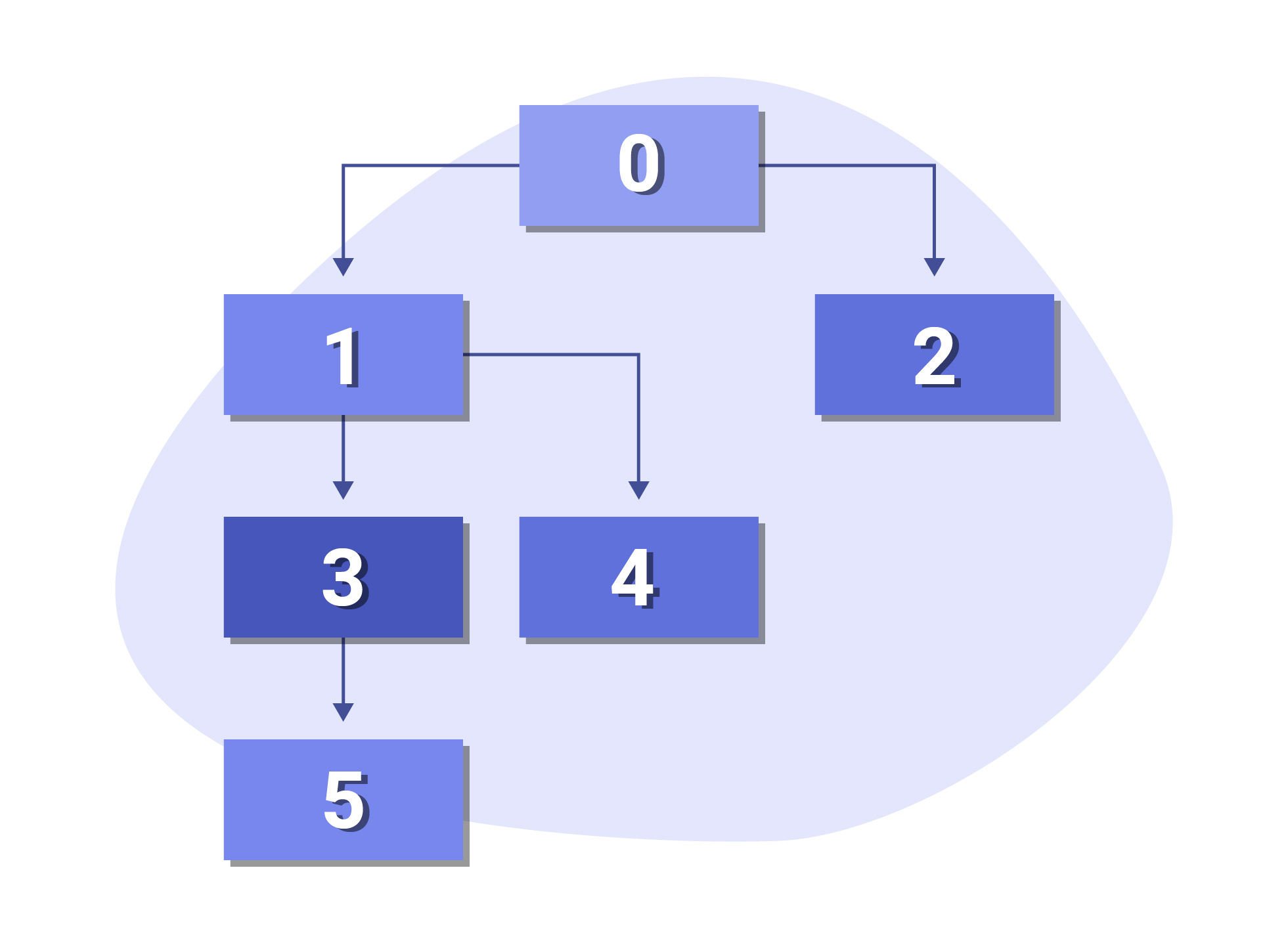
Breadth First Search Crawling
On the contrary, we have breadth first search crawling which traverses your website on a level-by-level basis i.e. it will only move onto the third level once it’s finished crawling the second level.
By traversing multiple categories in your website, BFS has the benefit of discovering more unique pages in a short period of time.
That being said, whilst BFS is good for preserving your site architecture, it can prove to be slow if your category pages take a long time to respond and load.
Efficiency Search Crawling
When it comes to efficiency search crawling, the crawler bases its crawl behaviour on server speed rather than the site structure.
In other words, if your website has been allocated a crawl budget of an hour, the spider will pick pages with the lowest response times first, and crawl those. This allows the web crawler to traverse more websites in a short period of time.
Therefore, it’s important to ensure that your website responds as quickly as possible to allow the crawler to traverse more web pages within its allocated time frame.
Here are some quick pointers on how to improve your server response time:
- Choose the right host and server
- Optimise and configure your web server – enabling a cache, using a content delivery network (CDN) and making sure you use HTTP/2 makes a huge difference in reducing the response time of your website.
- Eliminate Bloat – remove any programs, apps or plugins that you don’t need and may be dragging your response time lower.
- Optimise Your Existing Resources – optimisng your images, CSS and JavaScript files will go a long way in reducing response time.