In this chapter we dive into the Google BERT algorithm which uses the concept of Natural Language Processing to understand the sentiment and search intent of search queries.
Natural Language Processing (or NLP) refers to a branch of artificial intelligence and machine learning with the goal of helping computers to understand natural language.
You’ve probably come across the power of NLP without even realising it.
Ever had to “speak” to a robot when dealing with customer service on the phone or used a personal assistant application like Siri or OK Google on your phone?
Ever wondered how word processing tools like Microsoft Word and Grammarly are able to check the grammatical errors on your text?
They’re all using NLP to understand what you’ve said or typed.

As you’ve probably guessed by now, with the help of semantic web technologies and machine-learning, NLP is also a HUGE part of organic search.
However, before we unlock the enigma that is NLP, let’s take a look at the equally mystifying BERT – which is described by Google as their “biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search”.
Google BERT Algorithm
Announced by Google in October 2019, BERT is an algorithm update that precedes Google MUM (a more powerful iteration announced in 2021), and allows bots to understand the sentiment and search intent of search queries significantly better.
According to a statement from Google, a fully rolled out update impacted 10% of all searches.
Fast forward three months to January 2020, and Google has already followed through with a core algorithm update called January 2020 Core Update.
Later today, we are releasing a broad core algorithm update, as we do several times per year. It is called the January 2020 Core Update. Our guidance about such updates remains as we’ve covered before. Please see this blog post for more about that:https://t.co/e5ZQUA3RC6
— Google SearchLiaison (@searchliaison) January 13, 2020
There are hundreds if not thousands of smaller updates to Google’s algorithms every year, but the fact that Google gave the SEO world a heads up before rolling this one out, highlights its importance.
Although this tweet gives no insight into the specifics of what the algorithm focused on, the timing of this core update suggests that BERT and NLP have a big part in it.
So, let’s start off by taking a closer look at BERT, as it’s the key we’ll use to unlock the concept of NLP and these latest changes from Google.
What is BERT?
Originally introduced in 2018, BERT (which stands for Bidirectional Encoder Representations from Transformers) is an open-sourced technique based on neural networks for natural language processing pre-training using the plain text corpus of the English Wikipedia.
That’s right, the entire English Wikipedia!
Let’s look at one of the ways BERT helps understand contextual differences in language.
In the sentences “I play the bass guitar” and “I eat sea bass”, the word “bass” has two different meanings; it’s a polysemous word. Whilst this difference is more obvious to us humans, it’s not so simple for machines.

Likewise, BERT is able to comprehend other types of lexically ambiguous words and phrases such as homonyms, homophones, homographs, synonyms and more.
To summarise: BERT distinguishes subtle nuances in language to provide more relevant search results.
How Does BERT Work?
To gain a better understanding of how BERT works, we need to look at what the acronym actually stands for.
B: Bi-directional

The key to begin understanding how BERT and in turn how NLP works, is by looking at the first part of its name: Bidirectional.
The dictionary definition for “bidirectional” refers to two directions of a particular function or reaction.

This is the equivalent of Google calculating the meaning of a word of phrase by looking at the preceding and succeeding content.
The other part of the definition refers to the ability to learn (or react).
What makes BERT such a breakthrough, is its ability to learn language models based on an entire set of training data i.e. it looks at the entire set of words in a sentence or search query rather than simply moving through the sequence of words from left-to-right.
Putting the two together: BERT uses bidirectional training to learn the context of a word based on surrounding words rather than just the words that immediately precede or follow it.
Google refers to BERT as “deeply bidirectional” – it can “see” every word in a sentence simultaneously as well as understand how they impact the context of the other words in the sentence, rather than one at a time (unidirectional).
Unidirectional models try to predict the next word in a sequence (which is effective because they cannot “see” what the next word is), however this does not work for bidirectional models like MLM because it would enable it to indirectly “see” the word that it was trying to guess.
Masked Model Learning
Google achieves bidirectionality by training BERT using what’s called a Masked Learning Model (MLM).
By adopting a masked learning model, Google was able to train the natural language processors by “masking out some of the words in the input and then condition each word bidirectionally to predict the masked words”.
Let’s take the bizarre but illustrative sentence: “I love how you love that she loves that.”
As the sentence progresses, the part of text which the word “love” relates to changes along with the context of each use.
A unidirectional model would be unable to determine the full context of this sentence because it would only be able to “see” the preceding and succeeding words. In other words, if it looked at the first occurrence of “love”, it would only see “I” and “how”, but would not be able to see the rest of the sentence and in turn may miss the shape shifting context in this sentence.

BERT’s bidirectionality however, enables it to see the entire sentence from both directions – i.e. it sees each word at the same time – and as a result is able to consider the entire sentence’s context, like a human.

Textual Entailment
Taking things a step further, BERT is also trained to perform textual entailment, which is a more sophisticated way of saying that it is able to “predict the next sentence”.
In other words, given two sentences, BERT is able to predict whether or not the second sentence fits within the context of the first sentence.
In the examples below, BERT would be able to predict that the first set of sentences are contextually relevant, whereas the second pair of sentences are not.
Cricket is the best sport in the world.
My favorite player is Ben Stokes.
IsNextSentence
Cricket is the best sport in the world.
Water is a liquid.
IsNotNextSentence
ER: Encoder Representations

The Encoder Representations part of BERT’s name refers to its transformer architecture.
The sentence input is translated to representative models of the words’ meaning, this is known as the encoder.
The processed text output that is contextualised is known as the decoder.
Essentially, it’s an in-and-out situation where whatever is encoded (the text), is then decoded (the meaning).
T: Transformers
The final component of BERT is the transformers.
As we’ve already established, one of the main issues that NLP poses, is with not being able to understand the context of a particular word within a sentence.
We’ve already seen how it can be pretty easy for a machine to lose track of a subject within a sentence when varying pronouns are used.
So, one of the main purposes of the transformer, is to focus (or “fixate”) on both the meaning of any pronouns used, on top of the meaning of all other words used too. These are then used to try to piece the sentence together and contextualise the subject of the conversation or sentence – this is known as coreference resolution.
We’ve seen that one of the mechanisms that helps do this is MLM.
The Relationship Between BERT and NLP
We now know that BERT is built on two main components:
1. Data – the pre trained input models (sets of data)
2. Methodology – a defined way to learn and use those models
Providing BERT with an input set of data to learn from is all well and good, but you also need to define a process for BERT to be able to correctly understand and interpret this data.
This is where NLP comes into play.

The Impact of BERT and NLP On SEO
With billions of searches being made every day, understanding language has always been at the core of Search.
It’s the search engine’s job to work out what you’re searching for and provide helpful information from the web – regardless of what combination of words or spellings is used in the search query.
If we go back to why BERT exists in the first place (to improve machines’ understanding of human language) we can see how this all fits into place from an SEO perspective.
Natural language processing changes the way search engines understand queries at word level and through BERT, Google is able to resolve linguistic ambiguities in natural language by looking at each word in a sentence simultaneously.
The implications of BERT and NLP on SEO are humongous!
Let’s dive in and see exactly how these two powerful mechanisms impact SEO.
Contextualised SERPs
A change in the way search engines understand queries naturally impacts the search results themselves.
Featured Snippets
One of the areas in the SERPs that is affected, is the featured snippets.
Let’s take a look at an example of a featured snippet that Google themselves have provided for the query “parking on a hill with no curb”.
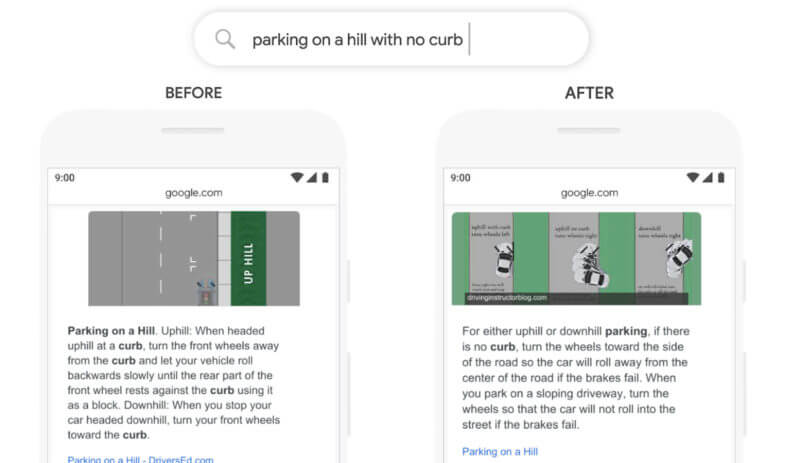
In the past, we can see that this query wasn’t quite understood correctly by Google’s systems. Google said that they ignored the word “no” and placed “too much importance” on the word “curb”.
Not being able to understand this critical word resulted in inappropriate results where Google would return results for “parking on a hill with a curb”.
Search Results for Textual Search Queries
Likewise, for queries that are more sophisticated or conversational, the meaning of propositions or stop-words (i.e. “and”, “to”, “in” and “for”) are more difficult to assess.
Here is an example from Google which shows how BERT’s improved understanding of the stop-word “to” provided better search results.

The query is about a Brazilian travelling to the U.S.A and not the other way around. However, Google returned results about U.S. citizens travelling to Brazil.
With BERT applied, Google is able to understand the importance of the relationship between the word “to” and the other words in the query better and in turn, is able to provide a much more relevant result to the user.
Improved Voice Search
BERT’s ability to be able to detect ambiguities in more conversational queries also extends to voice search.
This means that you can “speak” to Google as if you were speaking to an actual human.
For example, if you were to ask Google Assistant “What is Semantic SEO?”, instead of seeing a list of search results, Google will be able to answer your query using natural language.

Benefits to International Search
BERT is already being applied to Search across the world – this will present major benefits to the area of international search.
The beauty of BERT is that it is able to “take learnings from one language and apply them to others” which means that Google is able to take models that learn from improvements in English, and effectively transfer these learnings to other languages.
Structured Data Markup
With the combined power of BERT and NLP, any information you provide to Google about the content on a web page or your website in general, effectively has more meaning than ever before.
This makes marking up your content with structured data even more important and beneficial. In recent times, Google has promoted the usage of structured data by providing several case studies for businesses whose Search improved based on the quality of their schema.org markup.
Eventbrite, the world’s largest event technology platform reaped the rewards with “roughly a 100-percent increase in the typical year-over-year growth of traffic” when they marked up their event listings using the Event structured data markup.

BERT’s ability to understand natural language better enables it to grasp the information provided in the structured data markup, which in turn allows Google to index these pages more accurately so that they appear in the SERPs for more relevant terms.
How Does NLP Enhance Search Quality?
If 15% of all searches made online have never been seen by Google before, how is Google able to anticipate the intent behind the search term and provide relevant results?
The key to providing relevant results for unseen queries, is to understand language.
In order to understand language, we’ve already established that context is everything. On top of context, machines also need to be able to glean the sentiment of a query, be able to identify the subject (entity) of the queries and finally, the importance (salience) of the query.
You can see how Google “reads” your content by putting it into its Cloud Natural Language API Demo which uses machine learning AI and NLP to understand the text.
What is Sentiment in NLP?
Google needs to be able to identify what the underlying tone of content is in order to present the most relevant results for a particular search query.
Like emotion, sentiment can be analysed based on its polarity, i.e. it can be either positive, negative or neutral.
Positive Sentiment refers to when a topic is being described or discussed in a favourable tone and usually includes positive words like “awesome”, “legend”, “brilliant” etc.
In Google’s Natural Language API, the sentiment is considered as positive if the value is between 0.25 and 1.0.
Negative Sentiment, as you have probably already guessed, uses unfavorable language such as “bad”, “hate”, “upsetting” etc.
Negative sentiment falls within the range of -1.0 and -0.25
Neutral content contains a mix of both positive and negative language.
The resulting score range for neutral pieces of content falls within -0.25 and 0.25.
Google’s algorithm calculates the sentiment value based on each subsection of the content as opposed to the entire page.

What is The Entity in NLP?
An entity represents the subject or named object in a piece of text.
Examples of Google’s entity categories include persons, consumer goods, events, locations, numbers, organizations and more.
Google’s Natural Language AI uses NLP to identify and evaluate these entities within your content which enables it to obtain useful information that helps satisfy the user’s intent and present better search results.
Naturally, Google looks at nouns (aka naming words) and noun phrases (i.e. “the website ranks well”) to identify, classify and categorise entities. This also includes names (proper nouns), in fact, a research paper published by Google in 2014 focused primarily on people’s names.
Using Google’s Natural Language API demo, you can see exactly how entities are defined by the AI. We fed an article from the BBC on England cricketer Adil Rashid and we can see that the demo recognised that the following words all referred to the same person:
- Adil Rashid (named)
- Rashid (named)
- Spinner (nominal)

Google’s AI was able to understand that the word “spinner” was being used to refer to Adil Rashid.
Interestingly, it also classified “England” as an Organisation as opposed to a Location, as it understood that the article is talking about the England Cricket Team instead of the country.
Moreover, the AI also classifies the content into different categories, in this case /Sports/Team Sports/Cricket and /News/Sports News.

You can find a full list of categories here.
What is Salience in NLP?
In linguistics, the term salience refers to the prominence or importance of a word or phrase within a particular piece of content. In the case of NLP, it represents the importance of the entity within a piece of text.
As with sentiment, Google assigns each entity with a score based on its perceived salience in relation to the analysed text. This ranges from 0.0 to 1.0 where the higher the salience value, the more important and relevant the entity is for the page’s subject. This score is a prediction on what a human being would consider to be the most important entities within the same text.
For example, in our example from before, we can see that Google gives “Adil Rashid” the highest salience score of 0.69, which comes as no surprise, considering the article is about him.

Google bases this score on several numerical factors:
- The position of the entity within the text, i.e. the location of the first time the entity is discovered in the text – generally, entities placed closer to the beginning of the article are seen as more salient.
- The grammatical role of the entity i.e. the relationship between the subject and the object within a sentence.
- The entity’s linguistic links to other parts of the sentence, i.e. the most salient entities are usually grammatically linked within the sentence, you can see how Google breaks down each sentence’s words in the API Demo by clicking on the Syntax tab.
- A tally of the named, nominal and pronominal references to the entity (i.e. “Adil Rashid”, “spinner”, “he”) – naturally, the more an entity is mentioned, the higher salience Google is likely to give it.
Entity Graphs and Indexing
In the 2014 paper published by Dunietz and Gillick introduce the concept of an entity graph.
The entity graph is based on Google’s existing PageRank calculation which determines a page’s authority based on its incoming links. Google uses its own Knowledge Graph as its database of connected entities.
We’ve already encountered Google’s Knowledge Graph.
As a refresher, here’s what the knowledge graph for England cricket Ben Stokes looks like.

The entity graph’s primary purpose is to simulate the wider context for entities in a given piece of content, which humans would subconsciously draw upon. This is because as humans, we usually already know something about at least some of the entities involved, and importantly, we also have some idea of their salience.
Essentially, this enables the AI to adapt its salience scores for an entity based on its connections to other entities within the text.
In our example article about Adil Rashid, Yorkshire is given a higher salience score than West Indies even though both are mentioned only once within the text that was analysed.

This is because the AI has identified that Yorkshire is more closely related to the main topic of the article than West Indies.
This also ties to Google’s indexing infrastructure, which we know makes use of an inverted index and vectorisation to organise content in an efficient manner for easier retrieval.
If we imagine the index as being broken down into different entities.
Google pulls all of the content from a URL and describes it as a vector which includes certain characteristics of the page.
One of these key value pairs within the matrix describes the entities identified within the page and each of these, will be defined by their own vectors of key-value pairs. These include a salience score for each entity, as well as connected entities.
For example, if we looked at an article on Google, one of the entities may be it’s address (Mountain View, CA) and other characteristics such as when the company was founded, number of employees, turnover, profit etc would also be assigned their own salience score.
Here’s a JSON representation of how Google stores information about an Entity from one of its Cloud Docs :

In the above example, we can see that Google also keeps track of the number of mentions, a factor that we’ve already covered previously in this section.
RankBrain takes these vectors and compares the entities to determine whether they are relevant to each other.
In cases where there is no entity to match (i.e. it’s a query Google hasn’t seen before), the algorithm calculates the proximity of the closest entity that it can find and concludes that this is what the user is looking for.
Applications of Entity Salience in SEO
Although Google’s John Mueller has pretty much debunked entity salience as an important factor (see a tweet from him below), the fact that we know Google are assigning salience scores to entities and are looking at salience in order to understand language, implies that there is some value in optimising your content with entity salience in mind.
Where do you see that?
— 🍌 John 🍌 (@JohnMu) December 14, 2019
Moreover, Google’s Natural Language API page explicitly refers to Google Search in the following statement: “The Natural Language API offers you the same deep machine learning technology that powers both Google Search’s ability to answer specific user questions and the language-understanding system behind Google Assistant.”
By sharing this demo publically, we have a glimpse into how Google understands text, and as a result, we can optimise our text to make it easier for Google to do this.
So, let’s take a look at how you can apply the magic of entity salience within your content.
1. Text Position and Grammatical Function – you can use the ordering of words as well as grammatical tricks to boost the salience of entities that you want to target.
Below, we can see how the positioning of the words impacts the salience score that Google assigns to the entities.
Sentence 1: Frodo took the ring to Mordor.

Sentence 2: The ring was taken to Mordor by Frodo.

2. Linguistic Dependance – considering that NLP is powerful enough to “read” each word in a sentence at the same time (as opposed to one at a time), it means that processors like Google are able to understand linguistic relationships between words. We can see this in action by looking at the Syntax tab for the sentence “Frodo took the ring to Mordor”.

Google unpicks the relationships between each of these words to find the most salient entities by looking at several grammatical features.
For example, the green arrows depict dependencies between words for their meaning.
3. Entity References and Mentions – we have seen that Google keeps a tally of the number of mentions of a particular entity, therefore, a simple way to help increase the salience of an entity that you want to target, is to mention it more often. However, this should be done sparingly by incorporating a mixture of named (i.e. Adil Rashid), nominal (i.e. spinner) and pronominal (i.e. he) references.
It’s worth mentioning that Google is ultimately looking for naturally written content, so although entity salience holds some importance in increasing Google’s understanding of your text, it should be secondary to providing quality content to your audience.